
(Part 1 of 2 posts)
I’ve been percolating on this post for a long time. Thanks very much to Mark Burgess for reviewing early drafts of it.
One of the ideas that permeates our field of web operations is that we can’t have enough automation. You’ll see experience with “building automation” on almost every job description, and many post-mortem transcriptions around the world have remediation items that state that more automation needs to be in place to prevent similar incidents.
“AUTOMATE ALL THE THINGS!” the meme says.

But the where, when, and how to design, implement, and operate automation is not as straightforward as “AUTOMATE ALL THE THINGS!”
I’d like to explore this concept that everything that could be automated should be automated, and I’d like to take a stab at putting context around the reasons why we might think this is a good idea. I’d also like to give some background on the research of how automation is typically approached, the reasoning behind various levels of automation, and most importantly: the spectrum of downsides of automation done poorly or haphazardly.
(Since it’s related, I have to include an obligatory link to Github’s public postmortem on issues they found with their automated database failover, and some follow-up posts that are well worth reading.)
In a recent post by Mathias Meyer he gives some great pointers on this topic, and strongly hints at something I also agree with, which is that we should not let learnings from other safety-related fields (aviation, combat, surgery, etc.) go to waste, because there are some decades of thinking and exploration there. This is part of my plan for exploring automation.
Frankly, I think that we as a field could have a more mature relationship with automation. Not unlike the relationship humans have with fire: a cautious but extremely useful one, not without risks.
I’ve never done a true “series” of blog posts before, but I think this topic deserves one. There’s simply too much in this exploration to have in a single post.
What this means: There will not be, nor do I think should there ever be, a tl;dr for a mature role of automation, other than: its value is extremely context-specific, domain-specific, and implementation-specific.
If I’m successful with this series of posts, I will convince you to at least investigate your own intuition about automation, and get you to bring the same “constant sense of unease” that you have with making change in production systems to how you design, implement, and reason about it. In order to do this, I’m going to reference a good number of articles that will branch out into greater detail than any single blog post could shed light on.
Bluntly, I’m hoping to use some logic, research, science, and evidence to approach these sort of questions:
- What do we mean when we say “automation”? What do those other fields mean when they say it?
- What do we expect to gain from using automation? What problem(s) does it solve?
- Why do we reach for it so quickly sometimes, so blindly sometimes, as the tool to cure all evils?
- What are the (gasp!) possible downsides, concerns, or limitations of automation?
- And finally – given the potential benefits and concerns with automation, what does a mature role and perspective for automation look like in web engineering?
Given that I’m going to mention limitations of automation, I want to be absolutely clear, I am not against automation. On the contrary, I am for it.
Or rather, I am for: designing and implementing automation while keeping an eye on both its limitations and benefits.
 So what limitations could there be? The story of automation (at least in web operations) is one of triumphant victory. The reason that we feel good and confident about reaching for automation is almost certainly due to the perceived benefits we’ve received when we’ve done it in the past.
So what limitations could there be? The story of automation (at least in web operations) is one of triumphant victory. The reason that we feel good and confident about reaching for automation is almost certainly due to the perceived benefits we’ve received when we’ve done it in the past.
Canonical example: engineer deploys to production by running a series of commands by hand, to each server one by one. Man that’s tedious and error-prone, right? Now we’ve automated the whole process, it can run on its own, and we can spend our time on more fun and challenging things.
This is a prevailing perspective, and a reasonable one.
Of course we can’t ditch the approach of automation, even if we wanted to. Strictly speaking, almost every use of a computer is to some extent using “automation”, even if we are doing things “by hand.” Which brings me to…
Definitions and Foundations
I’d like to point at the term itself, because I think it’s used in a number of different contexts to mean different things. If we’re to look at it closely, I’d like to at least clarify what I (and others who have researched the topic quite well) mean by the term “automation”. The word comes from the Greek: auto, meaning ‘self’, and matos, meaning ‘willing’, which implies something is acting on its own accord.
Some modern definitions:
“Automation is defined as the technology concerned with the application of complex mechanical, electronic, and computer based systems in the operations and control of production.” – Raouf (1988)
‘Automation’ as used in the ATA Human Factors Task Force report in 1989 refers to…”a system or method in which many of the processes of production are auotmatically controlled or performed by self-operating machines, electronic devices, etc.” – Billings (1991)
“We define automation as the execution by a machine agent (usually a computer) of a function that was previously carried out by a human.” – Parasuraman (1997)
I’ll add to that somewhat broad definition functions that have never been carried out by a human. Namely, processes and tasks that could never be performed by a human, by exploiting the resources available in a modern computer. The recording and display of computations per second, for example.
To help clarify my use of the term:
- Automation is not just about provisioning and configuration management. Although this is maybe the most popular context in which the term is used, it’s almost certainly not the only place for automation.
- It’s also not simply the result of programming what were previously performed as manual tasks.
- It can mean enforcing predefined or dynamic limits on operational tasks, automated or manual.
- It can mean surfacing, displaying, and analyzing metrics from tasks and actions.
- It can mean making decisions and possibly taking action on observed states in a system.
Some familiar examples of these facets of automation:
- MySQL max_connections and Apache’s MaxClients directives: these are upper bounds intended on preventing high workloads from causing damage.
- Nagios (or any monitoring system for that matter): these perform checks on values and states at rates and intervals only a computer could perform, and can also take action on those states in order to course-correct a process (as with Event Handlers)
- Deployment tools and configuration management tools (like Deployinator, as well as Chef/Puppet/CFEngine, etc.)
- Provisioning tools (golden-image or package-install based)
- Any collection or display of metrics (StatsD, Ganglia, Graphite, etc.)
Which is basically…well, everything, in some form or another in web operations. 🙂
Domains To Learn From
In many of the papers found in Human Factors and Resilience Engineering, and in blog posts that generally talk about limitations of automation, it’s done in the context of aviation. And what a great context that is! You have dramatic consequences (people die) and you have a plethora of articles and research to choose from. The volume of research done on automation in the cockpit is large due to the drama (people die, big explosions, etc.) so no surprise there.
Except the difference is, in the cockpit, human and machine elements have a different context. There are mechanical actions that the operator can and needs to do during takeoff and landing. They physically step on pedals, push levers and buttons, watch dials and gauges in various points during takeoff and landing. Automation in that context is, frankly, much more evolved there, and the contrast (and implicit contract) there between man and machine is much more stark than in the context of web infrastructures. Display layouts, power-assisted controls…we should be so lucky to have attention like that paid to our working environment in web operations! (but also, cheers to people not dying when the site goes down, amirite?)
My point is that while we discuss the pros, cons, and considerations for designing automation to help us in web operations, we have to be clear that we are not aviation, and that our discussion should reflect that while still trying to glean information from that field’s use of it.
We ought to understand also that when we are designing tasks, automation is but one (albeit a complex one) approach we can take, and that it can be implemented in a wide spectrum of ways. This also means that if we decide in some cases to not automate something (gasp!) or to step back from full automation for good reason, we shouldn’t feel bad or failed about it. Ray Kurzweil and the nutjobs that think the “singularity” is coming RealSoonNowâ„¢ won’t be impressed, but then again you’ve got work to do.
So Why Do We Want to Use Automation?
Historically, automation is used for:
- Precision
- Stability
- Speed
Which sounds like a pretty good argument for it, right? Who wants to be less precise, less stable, or slower? Not I, says the Ops guy. So using automation at work seems like a no-brainer. But is it really just as simple as that?
Some common motivations for automation are:
- Reduce or eliminate human error
- Reduction of the human’s workload. Specifically, ridding humans of boring and tedious tasks so they can tackle the more difficult ones
- Bring stability to a system
- Reduce fatigue on humans
No article about automation would be complete without pointing first at Lisanne Bainbridge’s 1983 paper, “The Ironies of Automation”. I would put her work here as modern canonical on the topic. Any self-respecting engineer should read it. While its prose is somewhat dated, the value is still very real and pertinent.
What she says, in a nutshell, is that there are at least two ironies with automation, from the traditional view of it. The premise reflects a gut intuition that pervades many fields of engineering, and one that I think should be questioned:
The basic view is that the human operator is unreliable and inefficient, and therefore should be eliminated from the system.
Roger that. This supports the idea to take humans out of the loop (because they are unreliable and inefficient) and replace them with automated processes.
The first irony is:
Designer errors [in automation] can be a major source of operating problems.
This means that the designers of automation make decisions about how it will work based on how they envision the context it will be used. There is a very real possibility that the designer hasn’t imagined (or, can’t imagine) every scenario and situation the automation and human will find themselves in, and so therefore can’t account for it in the design.
Let’s re-read the statement: “This supports the idea to take humans out of the loop (because they are unreliable and inefficient) and replace them with automated processes.”…which are designed by humans, who are assumed to be unrelia…oh, wait.
The second irony is:
The designer [of the automation], who tries to eliminate the operator, still leaves the operator to do the tasks which the designer cannot think how to automate.
Which is to say that because the designers of automation can’t fully automate the human “out” of everything in a task, the human is left to cope with what’s left after the automated parts. Which by definition are the more complex bits. So the proposed benefit of relieving humans of cognitive workload isn’t exactly realized.
There are some more generalizations that Bainbridge makes, paraphrased by James Reason in Managing The Risks of Organizational Accidents:
- In highly automated systems, the task of the human operator is to monitor the systems to ensure that the ‘automatics’ are working as they should. But it’s well known that even the best motivated people have trouble maintaining vigilance for long periods of time. They are thus ill-suited to watch out for these very rare abnormal conditions.
- Skills need to be practiced continuously in order to preserve them. Yet an automatic system that fails only very occasionally denies the human operator the opportunity to practice the skills that will be called upon in an emergency. Thus, operators can become deskilled in just those abilities that justify their (supposedly) marginalized existence.
- And ‘Perhaps the final irony is that it is the most successful automated systems with rare need for manual intervention which may need the greatest investment in operator training.’
Bainbridge’s exploration of ironies and costs of automation bring a much more balanced view of the topic, IMHO. It also points to something that I don’t believe is apparent to our community, which is that automation isn’t an all-or-nothing proposition. It’s easy to bucket things that humans do, and things that machines do, and while the two do meet from time to time in different contexts, it’s simpler to think of their abilities apart from each other.
Viewing automation instead on a spectrum of contexts can break this oversimplification, which I think can help us gain a glimpse into what a more mature perspective towards automation could look like.
Levels Of Automation
It would seem automation design needs to be done with the context of its use in mind. Another fundamental work in the research of automation is the so-called “Levels Of Automation”. In their seminal 1999 paper “Human And Computer Control of Undersea Teleoperators”, Sheridan and Verplank lay out the landscape for where automation exists along the human-machine relationship (Table 8.2 in the original and most excellent vintage 1978 typewritten engineering paper)
| Automation Level | Automation Description |
| 1 | The computer offers no assistance: human must take all decision and actions. |
| 2 | The computer offers a complete set of decision/action alternatives, or |
| 3 | …narrows the selection down to a few, or |
| 4 | …suggests one alternative, and |
| 5 | …executes that suggestion if the human approves, or |
| 6 | …allows the human a restricted time to veto before automatic execution, or |
| 7 | …executes automatically, then necessarily informs humans, and |
| 8 | …informs the human only if asked, or |
| 9 | …informs him after execution if it, the computer, decides to. |
| 10 | The computer decides everything and acts autonomously, ignoring the human. |
This was extended later in Parasuraman, Sheridan, and Wickens (2000) “A Model for Types and Levels of Human Interaction with Automation” to include four stages of information processing within which each level of automation may exist:
- Information Acquisition. The first stage involves the acquisition, registration, and position of multiple information sources similar to that of humans’ initial sensory processing.
- Information Analysis. The second stage refers to conscious perception, selective attention, cognition, and the manipulation of processed information such as in the Baddeley model of information processing
- Decision and Action Selection. Next, automation can make decisions based on information acquisition, analysis and integration.
- Action Implementation. Finally, automation may execute forms of action.
Viewing the above 10 Levels of Automation (LOA) as a spectrum within each of those four stages allows for a way of discerning where and how much automation could (or should) be implemented, in the context of performance and cost of actions. This feels to me like a step towards making mature decisions about the role of automation in different contexts.
Here is an example of these stages and the LOA in each of them, suggested for Air Traffic Control activities:
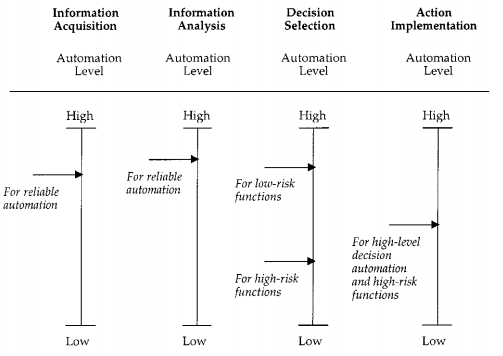
Endsley (1999) also came up with a similar paradigm of stages of automation, in “Level of automation effects on performance, situation awareness and workload in a dynamic control task”
What are examples of viewing LOA in the context of web operations and engineering?
At Etsy, we’ve made decisions (sometimes implicitly) about the levels of automation in various tasks and tooling:
- Deployinator: assisted by automated processes, humans trigger application code deploys to production. The when and what is human-centered. The how is computer-centered.
- Chef: humans decide on some details in recipes (this configuration file in this place), computers decide on others (use 85% of total RAM for memcached, other logic in templates), and computer decides on automatic deployment (random 10 minute splay for Chef client runs). Mostly, humans provide the what, and computers decide the when and how.
- Database Schema changes: assisted by automated processes, humans trigger the what and when, computer handles the how.
- Event handling: some Nagios alerts trigger simple self-healing attempts upon some (not all) alertable events. Human decides what and how. Computer decides when.
I suspect that in many organizations, the four stages of automation (from Parasuraman, Sheridan, and Wickens) line up something like this, with regards to the breakdown in human or computer function allocation:
| Information Acquisition |
|
| Information Analysis |
|
| Decision and Action Selection |
|
| Action Implementation |
|
Trust
In many cases, what level of automation is appropriate and in which context is informed by the level of trust that operators have in the automation to be successful.
Do you trust an iPhone’s ability to auto-correct your spelling enough to blindly accept all suggestions? I suspect no one would, and the iPhone auto-correct designers know this because they’ve given the human the veto power of the suggestion by putting an “x” next to them. (following automation level 5, above)
Do you trust a GPS routing system enough to follow it without question? Let’s hope not. Given that there is context missing, such as stop signs, red lights, pedestrians, and other dynamic phenomena going on in traffic, GPS automobile routing may be a good example of keeping the LOA at level 4 and below, and even then only sticking to the “Information Acquisition” and “Information Analysis” states, and keeping the “Decision and Action” and “Action Implementation” stages to the human who can recognize the more complex context.
In “Trust in Automation: Designing for Appropriate Reliance“, James Lee and Katrina A. See investigate the concerns surrounding trusting automation, including organizational issues, cultural issues, and context that can influence how automation is designed and implemented. They outline a concern I think that should be familiar to anyone who has had experiences (good or bad) with automation (emphasis mine):
As automation becomes more prevalent, poor partnerships between people and automation will become increasingly costly and catastrophic. Such flawed partnerships between automation and people can be described in terms of misuse and disuse of automation. (Parasuraman & Riley, 1997).
Misuse refers to the failures that occur when people inadvertently violate critical assumptions and rely on automation inappropriately, whereas disuse signifies failures that occur when people reject the capabilities of automation.
Misuse and disuse are two examples of inappropriate reliance on automation that can compromise safety and profitability.
They discuss methods on making automation trustable:
- Design for appropriate trust, not greater trust.
- Show the past performance of the automation.
- Show the process and algorithms of the automation by revealing intermediate results in a way that is comprehensible to the operators.
- Simplify the algorithms and operation of the automation to make it more understandable.
- Show the purpose of the automation, design basis, and range of applications in a way that relates to the users’ goals.
- Train operators regarding its expected reliability, the mechanisms governing its behavior, and its intended use.
- Carefully evaluate any anthropomorphizing of the automation, such as using speech to create a synthetic conversational partner, to ensure appropriate trust.
Adam Jacob, in a private email thread with myself and some others had some very insightful things to say on the topic:
The practical application of the ironies isn’t that you should/should not automate a given task, it’s answering the questions of “When is it safe to automate?”, perhaps followed by “How do I make it safe?”. We often jump directly to “automation is awesome”, which is an answer to a different question.
[if you were to ask]…”how do you draw the line between what is and isn’t appropriate?”, I come up with a couple of things:
- The purpose of automation is to serve a need – for most of us, it’s a business need. For others, it’s a human-critical one (do not crash planes full of people regularly due to foreseeable pilot error.)
- Recognize the need you are serving – it’s not good for its own sake, and different needs call for different levels of automation effort.
- The implementers of that automation have a moral imperative to create automation that is serviceable, instrumented, and documented.
- The users of automation have an imperative to ensure that the supervisors understand the system in detail, and can recover from
failures.
I think Adam is putting this eloquently, and I think it’s an indication that we as a field are moving towards a more mature perspective on the subject.
There is a growing notion amongst those who study the history, ironies, limitations, and advantages of automation that an evolved perspective on the human-machine relationship may look a lot like human-human relationships. Specifically, the characteristics that govern groups of humans that are engaged in ‘joint activity’ could also be seen as ways that automation could interact.
Collaboration, communication, and cooperation are some of the hallmarks of teamwork amongst people. In “Ten Challenges for Making Automation a ‘Team Player’ in Joint Human-Agent Activity” David Woods, Gary Klein, Jeffrey M. Bradshaw, Robert R. Hoffman, and Paul J. Feltovich make a case for how such a relationship might exist. I wrote briefly a little while ago about the ideas that this paper rests on, in this post here about how people work together.
Here are these ten challenges the authors say we face, where ‘agents’ = humans and machines/automated processes designed by humans:
- Basic Compact – Challenge 1: To be a team player, an intelligent agent must fulfill the requirements of a Basic Compact to engage in common-grounding activities.
- Adequate models – Challenge 2: To be an effective team player, intelligent agents must be able to adequately model the other participants’ intentions and actions vis-Ã -vis the joint activity’s state and evolution–for example, are they having trouble? Are they on a standard path proceeding smoothly? What impasses have arisen? How have others adapted to disruptions to the plan?
- Predictability – Challenge 3: Human-agent team members must be mutually predictable.
- Directability – Challenge 4: Agents must be directable.
- Revealing status and intentions – Challenge 5: Agents must be able to make pertinent aspects of their status and intentions obvious to their teammates.
- Interpreting signals – Challenge 6: Agents must be able to observe and interpret pertinent signals of status and intentions.
- Goal negotiation – Challenge 7: Agents must be able to engage in goal negotiation.
- Collaboration – Challenge 8: Support technologies for planning and autonomy must enable a collaborative approach.
- Attention management – Challenge 9: Agents must be able to participate in managing attention.
- Cost control – Challenge 10: All team members must help control the costs of coordinated activity.
I do recognize these to be traits and characteristics of high-performing human teams. Think of the best teams in many contexts (engineering, sports, political, etc.) and these certainly show up. Can humans and machines work together just as well? Maybe we’ll find out over the next ten years. 🙂
“The question is no longer whether one or another function can be automated, but, rather, whether it should be. – Wiener & Curry (1980)”
“…and in what ways it should be automated.” – John Allspaw (right now, in response to Wiener & Curry’s quote above)
Pingback: Today in bookmarks for September 21st. | ngerakines.me
Looking forward to the series! FYI your link to the Parasuraman paper is broken (case sensitivity). Correct link is http://archlab.gmu.edu/people/rparasur/Documents/ParasSherWick2000.pdf
Jon: thanks! Appreciate the kind words, and picking up the typos. (fixed)
Pingback: Automation » Mind End | Mind End
You’ve covered a lot of ground — and about 30 yrs of exploration of automation and human performance. I’d add the following observations:
Irony on top of irony
First, an irony of automation that Lisanne Bainbridge did not include is that the human activities most susceptible to the ironies of automation are those of designing, creating, and maintaining automation itself. The original inquiries into automation (clearly beginning with Norbert Wiener’s 1950 book The Human Use of Human Beings) recognized the tension between relieving humans of repetitive, boring tasks and disconnecting humans from the world on which they depend. Both Norbert and Bainbridge were thinking about tasks then done by humans — mainly manual work and manual control of machines. But nowhere are the ironies of automation seen more clearly than in IT itself. What are advanced scripting languages but the automation of automation? What, after all, is the unix command make? Looking at modern IT system failures beginning with AT&T’s Thomas Street outage in 1991 the automation associated with IT and, particularly, its maintenance, demonstrates that automation itself has all the ironies Bainbridge and others have identified.
Task allocation is a kind of design failure
Second, the survey in your blog post suggests the evolution of the understanding of automation and its discontents. A particular middle point (and dead end!) in this evolution was the move towards task allocation. The idea here is that successful managing automation is a matter of getting the right allocation of some tasks to humans and others to automation. This idea is now thoroughly discredited because it fails to recognize that doing this does not free the humans from the responsibility for the operations of the system and does not relieve them of the need to understand and influence the automation itself. Ironically [!] task allocation can actually make the human’s work even harder because successful control of the larger system requires that the human operator understand not only the underlying machinery of the system but also how the automation views the workings of this machinery and how the automation will respond to future inputs from the system and the human operator. Even worse, the requirement to bring these understandings together and make decisions often occurs under great pressure: people have to be able to do mental simulation of the automation’s likely behavior when there is a novel threat, e.g. when the system is beginning to fail. For this reason, a designer’s resort to task allocation as a strategy for designing automation is a sign of design failure. If you see task allocation being employed you know that the designers don’t ‘get it’.
Can I make a quick plug for *autonomic computing* ?
http://queue.acm.org/detail.cfm?id=1122689
http://www.research.ibm.com/autonomic/
You’ve got a great list of the problems and considerations in automation. As well as the need for it in IT, or rather the severely limited extent of it, in these days of devops and cloud (and people who believe deployment = orchestration, and triggers = automation).
While autonomics is far from solving it (and these articles are old), the approach gives some of the most useful principles I’ve found for “automating all the things”: organize management logic hierarchically, corresponding to systems or pieces of systems or groups of systems, with sensors and effectors at each element in the hierarchy, trying to manage things locally but escalating when they need to.
The parallel to how humans organize is very strong — as you suggest it should be — and also of course to systems in the body.
Alex: thanks for the comment. I’ve been aware of IBM’s ‘autonomic’ computing, and it’s fascinating. It feels like progress from the traditional view on fault tolerance, resource allocation within the machines, etc. It appears to have legs.
I feel that what Autonomic computing is missing is a human factors contingent of research. Something that the literature is missing is discussion on its relationship to human operators. Observability and , inspectability, and direct-ability are some of the key pieces that out to be considered to be requirements in automated systems. I think we ought to see how IBM’s research turns out, but they have an opportunity to take these challenges on early in the research. I hope they will.
Pingback: IT Automation Digest for October 26, 2012 | Puppet Labs
This was a fantastic overview of automation! Your analysis is spot on and timely. Over my career I have seen a lot of automation for the sake of automation (and I have been guilty of it myself). There is huge rush when you see well-designed automation obliterate what would have been hours worth of work down to minutes, or even seconds. That need for that adrenaline rush of accomplishment often overrides and avoids a more mature consideration of all of the implications of what you are doing. In short, we need IT systems engineers to act more like engineers in mechanical, chemical, nuclear, etc. fields. Maybe this is just the long overdue maturation of the IT industry. I mean – why aren’t there more serious certifications for automation in IT? Considering the millions of dollars on the line for companies running serious operations, it is a little crazy.
As an aside here – It would be really interesting if you commented in your series on choosing automation based on business priorities. In particular, how do prioritize and guide automation efforts to provide the maximum value for the business.
Pingback: Let’s talk about maturity in automation « Newtonian Nuggets
Pingback: AWS outage » Mind End | Mind End
Great post and deep overview about IT Automation > As Ben mentioned I would add how to choose a tool that fits to your level of automation!
I personally wrote a post on that in my run book Automation blog: 7 Key Questions to Ask When Evaluating IT Process Automation Tools http://bit.ly/SYwxQi
great effort sir, please guide me on automation in aviation, i have to deposit a search paper
Pingback: This week in DevOps #4 | Dev Ops Guys
Pingback: Automate all the things. | Constantine
Pingback: April Pocket link collection with 27 links
Pingback: Datadog - The best of Velocity and DevOpsDays 2013 (part II)
Pingback: Sharing is a competitive advantage - O'Reilly Radar
Pingback: Sharing is a competitive advantage - Programming - O'Reilly Media
Pingback: Why the Velocity Conference is coming to New York - Forbes
Pingback: Counterfactual Thinking, Rules, and The Knight Capital Accident | Kitchen Soap
Pingback: Sharing is a competitive advantage - O'Reilly Radar
Pingback: Kitchen Soap – A Mature Role for Automation: Part II
Pingback: Brainiac Corner with Katherine Daniels | MySQL
Pingback: Violently Mild » Deployment Contracts
Pingback: Automation should be like Iron Man, not Ultron-IT大é“
Pingback: Automation should be like Iron Man, not Ultron | Daily Hackers News
Pingback: Automation should be like Iron Man, not Ultron | Jkab tekk
Pingback: Automating Incident Response: Setting the Stage | Cyber Triage
Pingback: Feature Release Maturity Model - Rollout Blog
Pingback: You Might Not Need Continuous Deployment - Split